BGINFO - A Posh Recreation
Recently I have been building a lot of Windows Servers in different environments - one
Its been a few months since I wrote about my new project PasteHunter When I first wrote the app it was a fairly simple single threaded app that followed a simple work flow:
This was a good start but I wanted more. So I spent a few months testing and iterating new methods and modules. This also included adding modular support for other data inputs. Sites like GitHub were easy to add however it should be possible to scrape websites or forums as well. Look for an RSS feed from there grab each new entry to the website and pass the URL to the Queue, Pastehunter will take care of collecting the raw content and scanning it.
What I ended up with, what I am releasing as Version 1.0 today, is a multithreaded app that can query multiple sites, write to multiple outputs and has post processing capabilities as well.
The new workflow looks a bit like this
It does a couple of other things as well like the SMTP reporting module Which can be configured to only alert on specific yara rules rather than all of them.
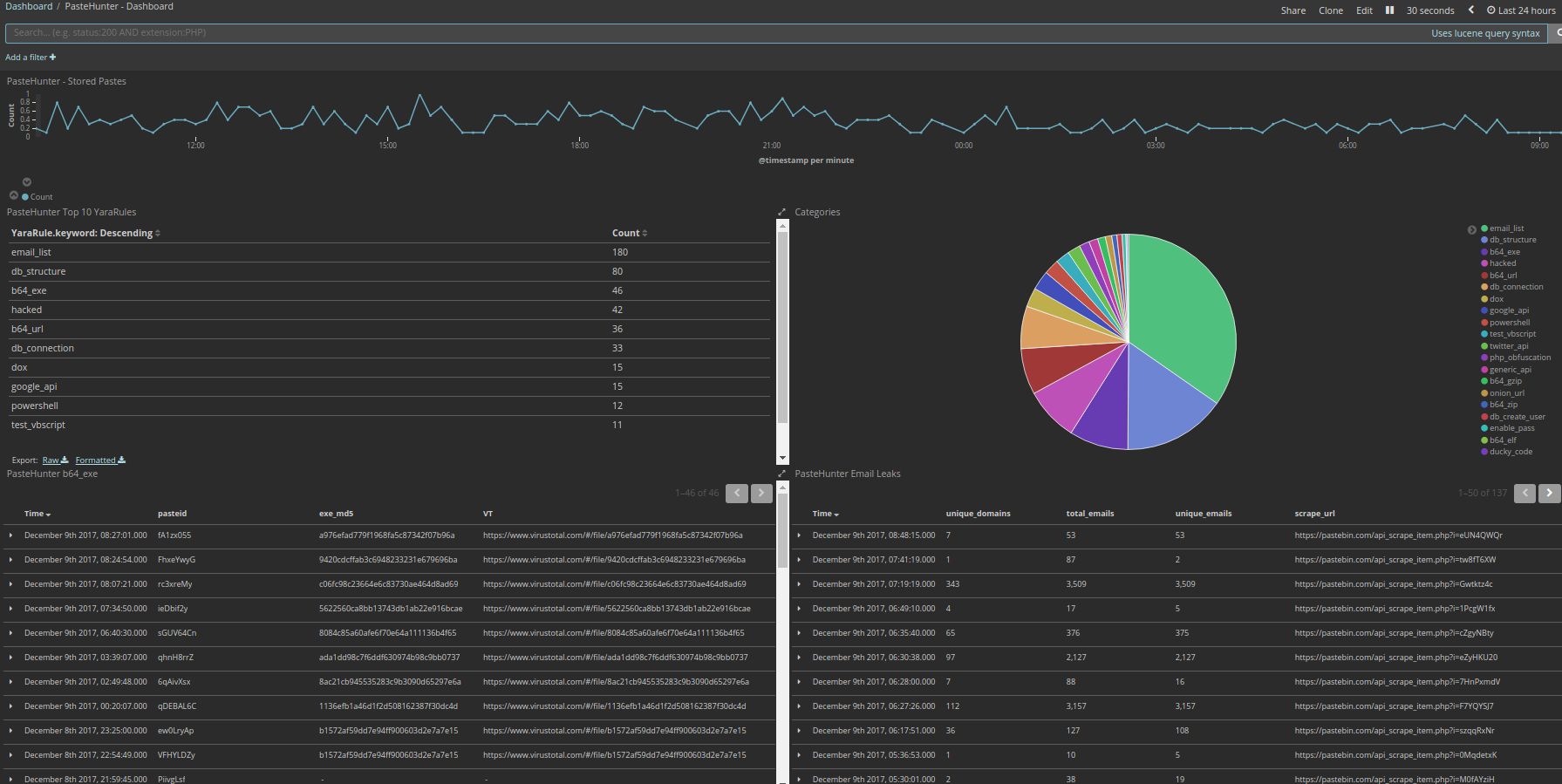
My standard setup is to write everything to an ELK stack. Its just easy to get data in and visualize it without building something of my own. This is what a typical dashboard for a 24 Hour period looks like
If you would like the Kibana Dashboard grab this dashboard.zip that has the JSON Files for import.
The Email List signature is a bit loose and catches a lot of things that are not straight up email dumps. However because it is loose it also captures some other interesting things!
At the time of writing here is a list of rules that are currently included out of the box:
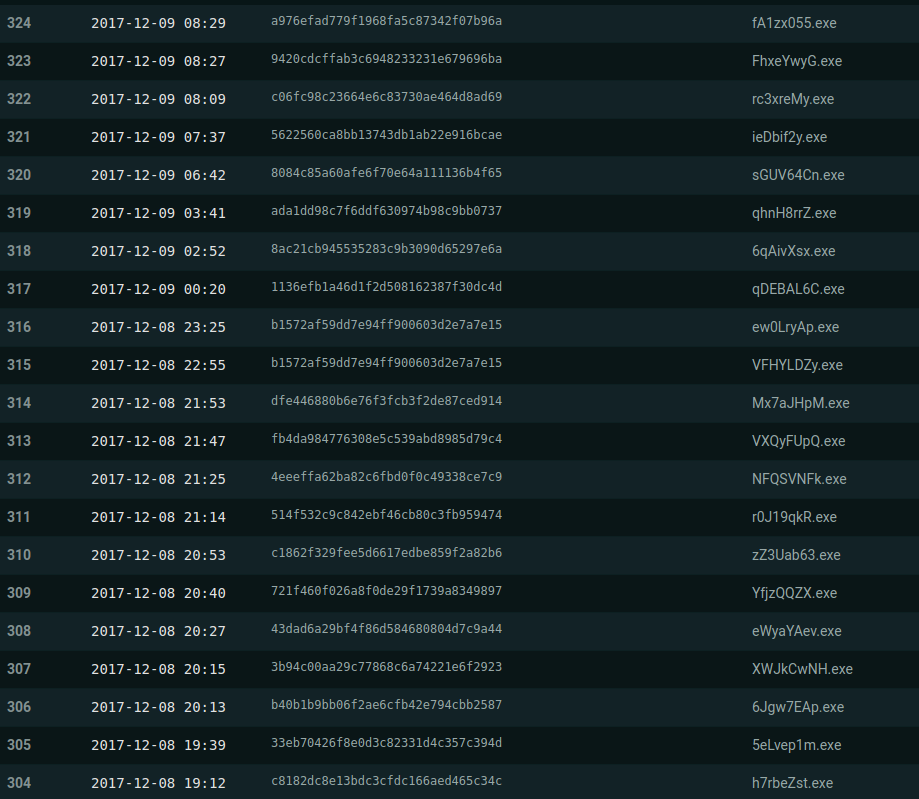
There is a lot of base64 encoded content on pastebin. Its an easy way to share files. By far the largest use of base64 i have found so far is in distributing exe files. And almost all of this content is malware.
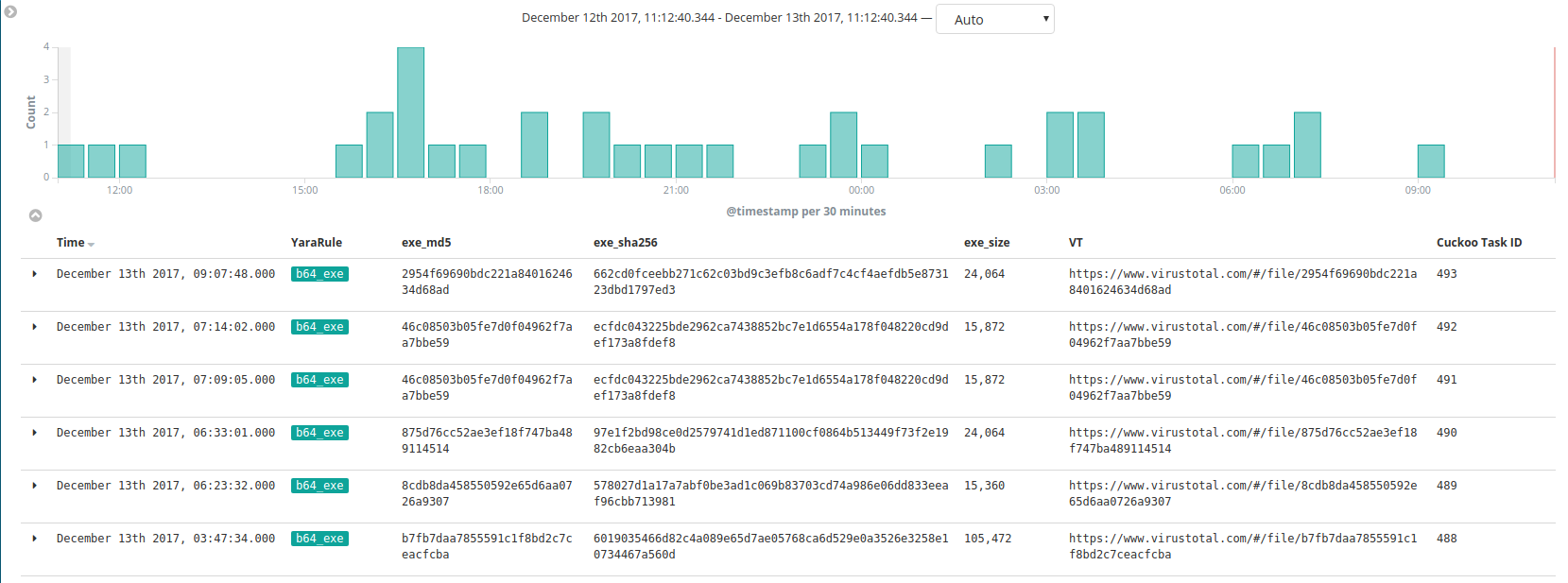
On average there are 40 encoded exe files uploaded to pastebin every day. I was interested in seeing what was in these binaries and that led me to create a post process workflow for PasteHunter.
The first workflow I created was to decode the b64 files and send them to a cuckoo sandbox.
There are a lot of emails pushed to pastebin and I mean a lot of emails. in the last 24 hours PasteHunter has recorded 462,260 email addresses. Or to be more accurate 462,260 items that match an email address format.
Most of the email lists look like this.
I figured this was also a rule that could benefit from a post processing module. From a quick analytics perspective I thought it might be useful to extract the unique emails and unique domains. The idea being if you spot 1000 emails with 1 unique domain that is possibly more interesting than 100 emails with 60 domains.
Which means we can now see the data like this.
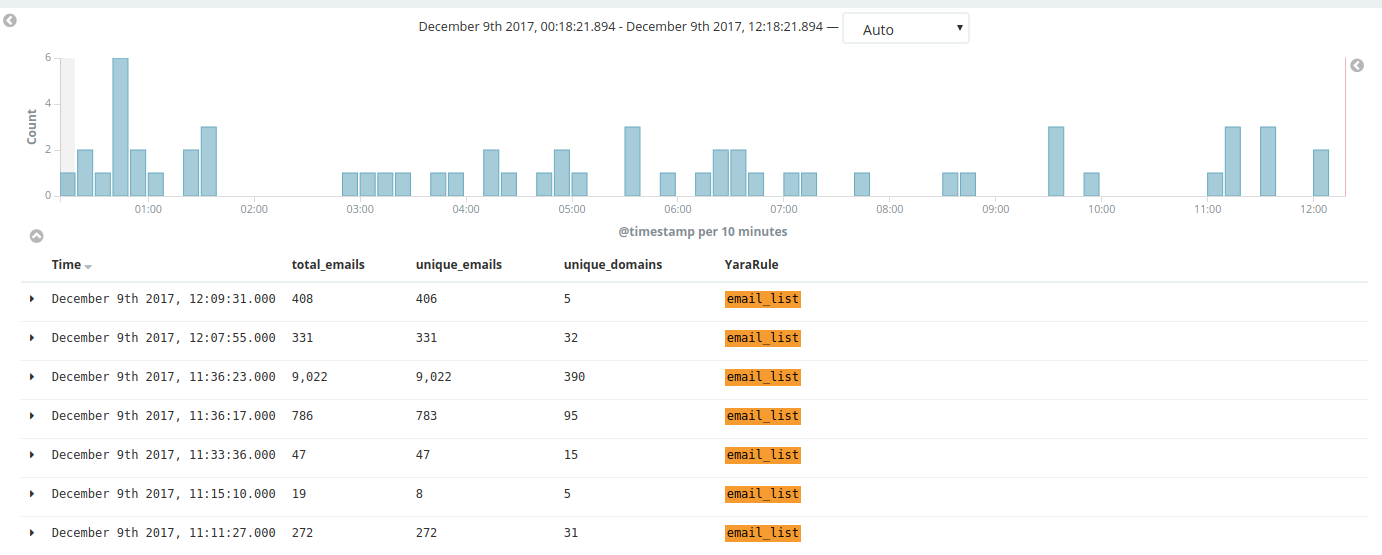
There are other things planned with the email post processing module like more false postive reduction, parsing passwords / hashes from the content.
The email list rule also discovers items like this.
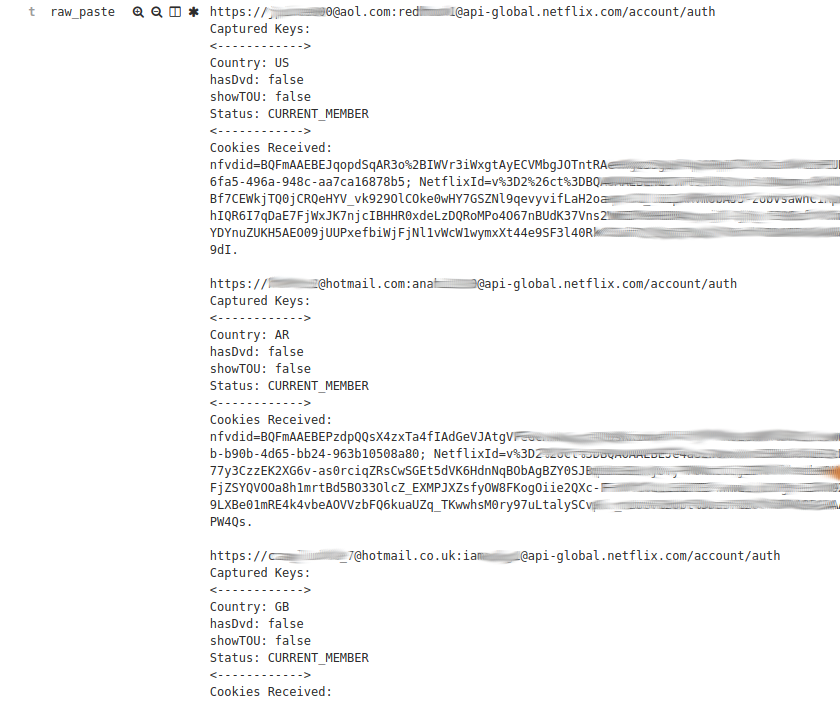
This appears to be a list of compromised netflix user accounts. The addition of captured cookies is interesting.
And this that appears to be a list of cloudflare accounts. With this kind of information you could start redirecting domains and controlling DNS for each of the domains.
An old email rule that wasnt very well tuned also hit on this. An XML page that contains a lot of information on a single person including Bank Details, Driving License, Address, SSN and more.

I was crafting rules for API Keys and I was also updating one of my twitter API’s so figured might as well throw a rule up for these as well. A lot of the matches are code fragments without the details. But every now and again. . .

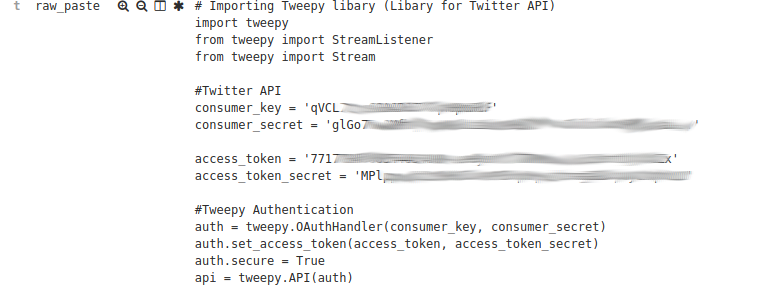
This is a general set of rules that look for API Keys and Access tokens and other items.
There are so many of these I could fill this post for pages and pages and pages. . . It is a scary amount of API keys and web configs that get shared on a site like pastebin.
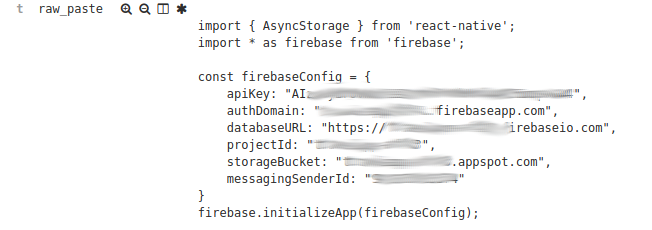
From simple things like Firebase apps
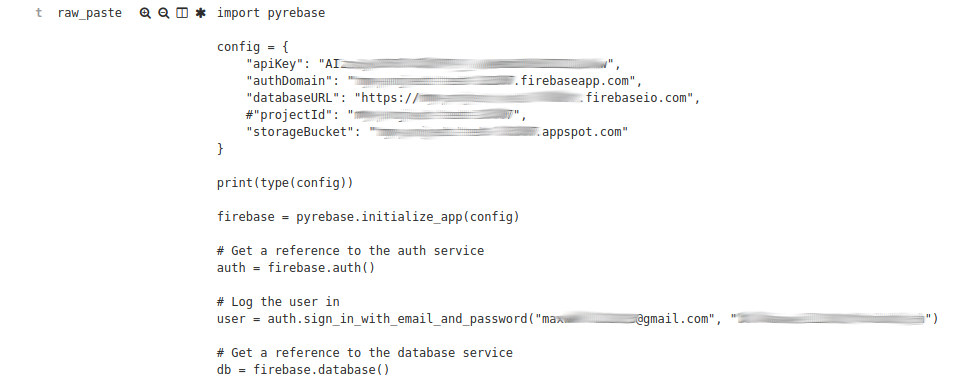
And Bitcoin Exchanges

To full blown web config files

If API Keys are not bad enough there are also plenty of Database details floating around.
Lots of Mongo Databases
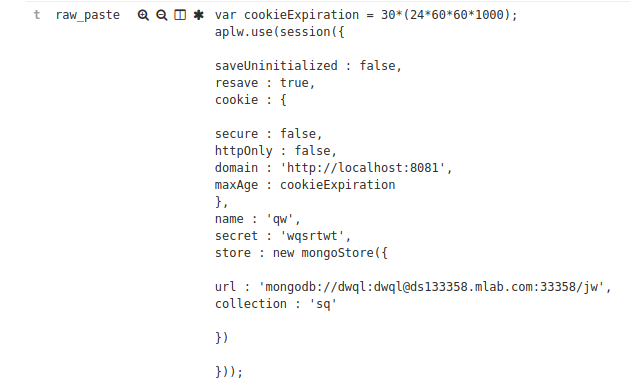
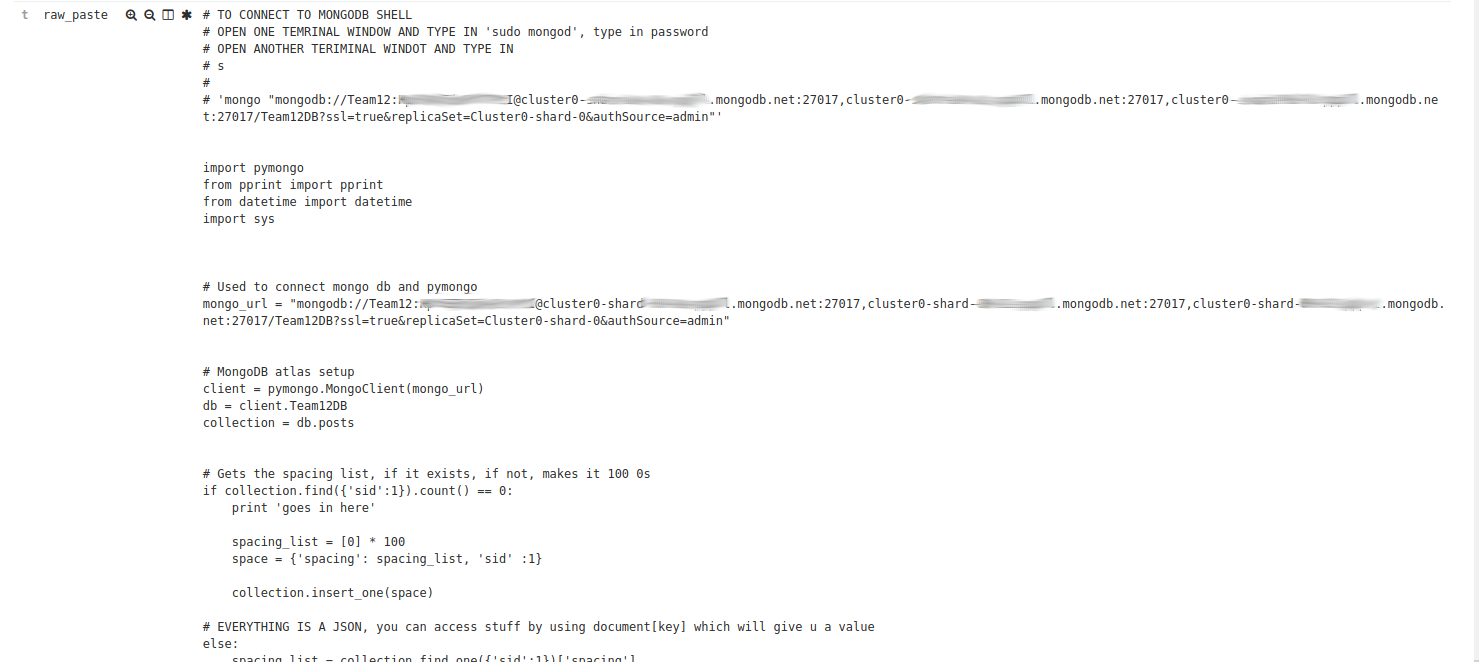
MySQL Databases
There are also plenty of others like FTP links with passwords HTTP Links with basic auth creds inline.
This is just a handfull of items that I have spotted in the last 24 Hours as I put this post together. There is a lot more out there. I have found ansible playbooks, ftp creds with links to vagrant builds and the box files that go along with them.
The hardest thing I have found is trying to report some of the things that I find. Sometimes I get an answer back, most of the time my messages are ignored, or at the very least not responded to.
The final thing to note is that there is no validation performed on any of the data. Due to the very nature of the platform the content is anonymous and has a very low level of trust. The list of email addresses could be fake, could be 5 years old and just re-pasted.
For those of you who would use PasteHunter to store every paste there is a field that contains the MD5 or the raw paste. The plan is to use this track repeated data over time.